In recent years, the field of artificial intelligence has seen significant advancements, particularly with the emergence of multimodal models. These models have the ability to process and integrate data from multiple modalities, such as text, images, audio, and video. This article delves into the fundamental concepts of multimodal models, their significance, applications, and future prospects.
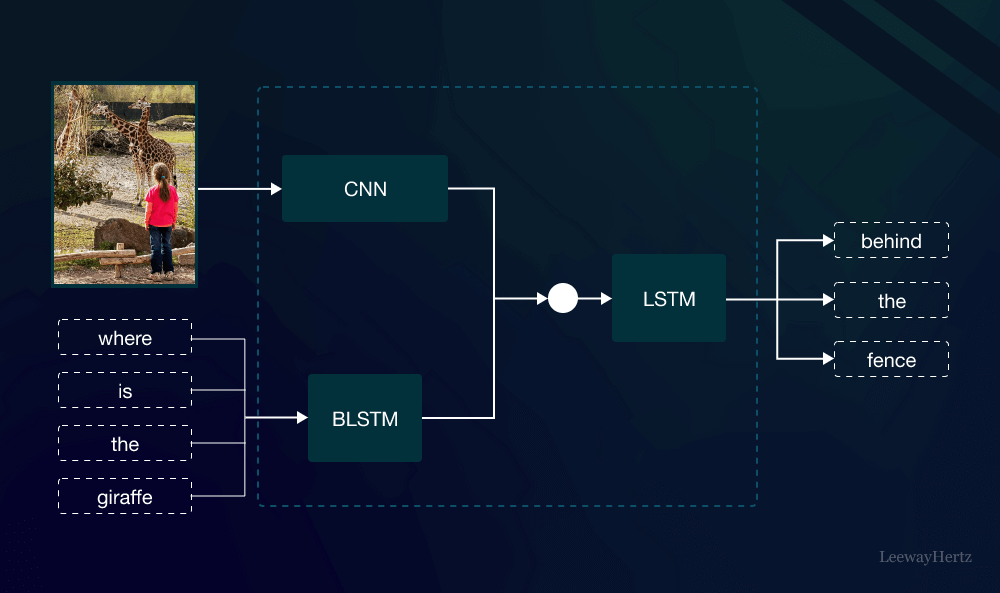
What Are Multimodal Models?
Multimodal models are sophisticated systems designed to understand and generate information by utilizing various types of data inputs. Unlike traditional models that typically focus on a single type of data, multimodal models harness the strengths of different modalities, enabling them to produce richer and more nuanced outputs. For instance, a multimodal model could analyze a video alongside its transcript to better understand the context and meaning behind the content.
The Importance of Multimodal Models
The ability to integrate diverse data types is what makes multimodal models particularly powerful. This integration allows for a more comprehensive understanding of complex information, which can enhance decision-making processes in various domains. For example, in healthcare, multimodal models can analyze patient records, medical images, and genomic data simultaneously to assist in diagnosis and treatment planning.
Furthermore, these models can improve user experience in applications such as virtual assistants and customer service bots. By understanding context through various data types—like spoken language, user behavior, and visual cues—multimodal models can provide more relevant and personalized responses.
Key Components of Multimodal Models
Data Representation
One of the foundational aspects of multimodal models is effective data representation. Each type of data—whether it be text, images, or audio—requires specific techniques for representation. For instance, images are often transformed into numerical arrays using convolutional neural networks (CNNs), while text is processed through embedding techniques like word embeddings or transformer models.
Fusion Techniques
After data representation, the next step is to fuse these different modalities effectively. Fusion techniques can be categorized into three main types:
- Early Fusion: This approach involves combining data from multiple modalities at the initial stage, allowing the model to learn shared representations.
- Late Fusion: In this method, each modality is processed separately, and their outputs are combined later. This is often useful when modalities are highly specialized.
- Hybrid Fusion: This technique combines both early and late fusion methods to leverage the strengths of each approach, resulting in more robust multimodal models.
Training and Optimization
Training multimodal models can be challenging due to the diverse nature of the data involved. Techniques such as transfer learning and multi-task learning are often employed to enhance the model’s ability to generalize across different tasks and data types. Additionally, optimization algorithms must be tailored to address the unique characteristics of the data modalities being used.
Applications of Multimodal Models
Natural Language Processing
In the realm of natural language processing (NLP), multimodal models are revolutionizing the way machines understand human communication. By incorporating visual elements, such as images or videos, these models can better interpret context and sentiment in textual data. For example, a multimodal model analyzing social media posts can consider both the text and accompanying images to derive a more accurate understanding of public sentiment on a particular topic.
Healthcare
In healthcare, multimodal models are paving the way for personalized medicine. By analyzing various data types—like electronic health records, medical images, and genomic data—these models can provide insights into patient conditions and treatment outcomes. This comprehensive approach can lead to more accurate diagnoses and tailored treatment plans, ultimately improving patient care.
Autonomous Systems
Autonomous systems, such as self-driving cars, rely heavily on multimodal models. These vehicles must process data from cameras, LIDAR, and GPS systems simultaneously to navigate and make real-time decisions. The integration of various data types enables these systems to understand their environment better, leading to safer and more efficient operation.
Future Prospects of Multimodal Models
The future of multimodal models is promising, with ongoing research focusing on improving their capabilities and expanding their applications. As data generation continues to increase, the need for effective integration and understanding of diverse modalities will grow. Advancements in computational power and algorithms will enable the development of more sophisticated multimodal models capable of addressing complex real-world challenges.
Moreover, the ethical implications of multimodal models are gaining attention. As these models become more prevalent, ensuring fairness, transparency, and accountability will be crucial. Researchers are exploring methods to make multimodal models more interpretable, helping users understand how decisions are made based on the integrated data.
Conclusion
In conclusion, multimodal models represent a significant leap in the field of artificial intelligence. By effectively integrating various data types, these models offer enhanced understanding and more nuanced outputs. Their applications span across multiple domains, from natural language processing to healthcare and autonomous systems. As technology advances, the potential of multimodal models will continue to expand, making them a vital area of study and development in AI. Understanding and harnessing the power of multimodal models will undoubtedly play a crucial role in shaping the future of intelligent systems.

Leave a comment