Introduction to Parameter-Efficient Fine-Tuning (PEFT)
In the evolving landscape of machine learning, Parameter-efficient Fine-tuning (PEFT) has emerged as a pivotal approach to optimize pre-trained models for specific tasks. Unlike traditional fine-tuning methods that require adjusting a large number of parameters, PEFT focuses on modifying only a small subset. This article explores the concept of PEFT, its benefits, various techniques, and the training process involved.
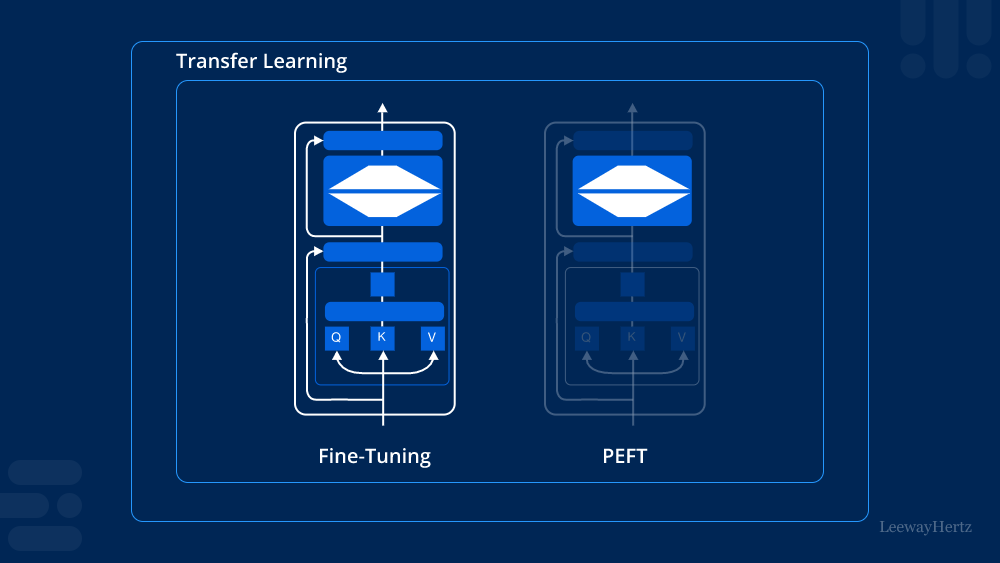
The Need for Parameter-Efficient Fine-Tuning
As machine learning models grow in size and complexity, the computational resources required for training become increasingly demanding. Traditional fine-tuning methods involve retraining entire models, leading to longer training times and higher costs. Parameter-efficient Fine-tuning (PEFT) addresses these challenges by allowing practitioners to achieve competitive performance while minimizing resource consumption.
Benefits of Parameter-Efficient Fine-Tuning (PEFT)
- Reduced Resource Consumption: One of the most significant advantages of PEFT is its ability to reduce the amount of computational power and memory required for model training. By focusing on a limited number of parameters, it enables faster experimentation and deployment.
- Faster Training Times: With fewer parameters to adjust, the training process becomes quicker. This efficiency is particularly beneficial in environments where time is critical, allowing organizations to iterate on models rapidly.
- Improved Generalization: Parameter-efficient Fine-tuning (PEFT) can help improve the generalization of models. By tuning only a few parameters, models can retain much of their pre-trained knowledge, resulting in better performance on unseen data.
- Lower Risk of Overfitting: Since fewer parameters are involved, the risk of overfitting is significantly reduced. This makes PEFT an attractive option for tasks where the training dataset is small or limited.
Techniques in Parameter-Efficient Fine-Tuning (PEFT)
There are several techniques within the realm of PEFT that practitioners can employ:
1. Adapter Layers
Adapter layers are lightweight modules inserted between the layers of a pre-trained model. Instead of modifying the entire model, only the parameters of these adapter layers are trained, allowing for efficient updates while preserving the model’s foundational knowledge.
2. Low-Rank Adaptation (LoRA)
Low-Rank Adaptation is a technique that approximates the weight updates of a model using low-rank matrices. By learning these low-rank updates, PEFT achieves efficient fine-tuning without the need to alter all model parameters.
3. Prompt Tuning
Prompt tuning involves fine-tuning models by optimizing a small number of input prompts instead of adjusting the model’s weights directly. This technique is particularly effective for language models, where the prompt can significantly influence the output.
4. BitFit
BitFit focuses on fine-tuning only the bias terms of a model while keeping the weights frozen. This method has shown that minor adjustments can lead to substantial performance improvements, highlighting the power of parameter-efficient updates.
Model Training with Parameter-Efficient Fine-Tuning (PEFT)
Training a model using Parameter-efficient Fine-tuning (PEFT) involves several key steps:
Step 1: Selecting a Pre-trained Model
The first step is to choose an appropriate pre-trained model based on the specific task at hand. Models should have a strong foundation relevant to the new task to ensure effective fine-tuning.
Step 2: Choosing a PEFT Technique
Depending on the resources available and the nature of the task, select a suitable PEFT technique such as adapter layers, LoRA, prompt tuning, or BitFit. Each technique has its strengths and is best suited for different scenarios.
Step 3: Setting Up the Training Environment
Prepare the training environment by configuring the necessary hardware and software. This setup should be optimized to handle the computational requirements of the chosen PEFT technique.
Step 4: Fine-Tuning the Model
Initiate the fine-tuning process by training only the selected parameters. Monitor the training closely to ensure that the model is learning effectively without overfitting.
Step 5: Evaluating Performance
Once training is complete, evaluate the model’s performance on a validation dataset. This step is crucial for assessing the effectiveness of the Parameter-efficient Fine-tuning (PEFT) approach and making any necessary adjustments.
Conclusion
Parameter-efficient Fine-tuning (PEFT) represents a significant advancement in the field of machine learning, offering a practical solution for optimizing pre-trained models while conserving resources. By focusing on a limited set of parameters, PEFT enables faster training, improved generalization, and a reduced risk of overfitting. As the demand for efficient and effective machine learning solutions grows, understanding and implementing PEFT techniques will become increasingly important for practitioners aiming to leverage the full potential of their models.

Leave a comment