Introduction
Multimodal Models are transforming the field of artificial intelligence (AI) by integrating multiple forms of data—such as text, images, audio, and video—into a single model. These models enhance the ability of machines to understand and generate human-like responses, making them a cornerstone of advanced AI systems. In this article, we will explore what Multimodal Models are, how they work, their benefits, challenges, and their impact on various industries.
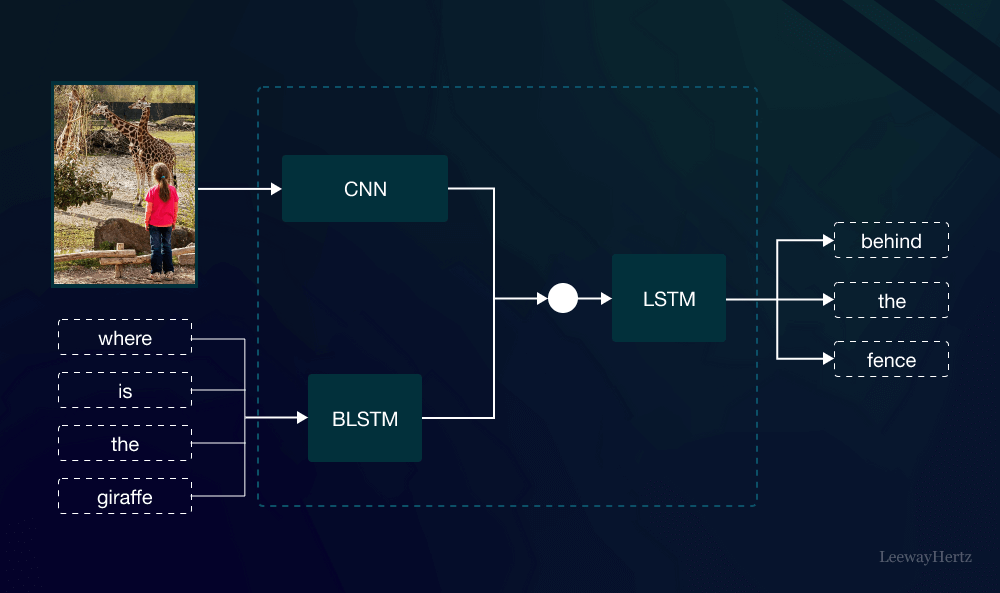
What Are Multimodal Models?
Multimodal Models are AI systems that process and interpret data from multiple modalities or sources. Unlike traditional AI models that rely on a single type of data, such as text or images, Multimodal Models can handle complex data inputs from different modalities simultaneously. For example, a Multimodal Model can analyze a combination of text and images to generate a comprehensive response, providing a more nuanced understanding of the input data.
How Do Multimodal Models Work?
At their core, Multimodal Models use advanced neural networks to combine and process data from different modalities. The process involves the following steps:
- Data Representation: Each type of data is represented in a format that the model can understand, often using embeddings. For instance, text is converted into word vectors, while images are represented as pixel values.
- Feature Extraction: The model extracts relevant features from each data type. For example, it identifies patterns in text, such as sentiment or keywords, while analyzing visual elements in images like shapes or colors.
- Fusion of Modalities: The extracted features from each modality are then combined, or “fused,” into a unified representation. This fusion process enables the model to leverage information from multiple sources, enhancing its overall understanding.
- Output Generation: Finally, the model generates an output based on the fused information. This could be a prediction, classification, or a more complex response, such as generating descriptive text for an image.
Benefits of Multimodal Models
Multimodal Models offer several advantages that make them increasingly popular in AI research and applications:
- Improved Accuracy: By leveraging multiple data sources, Multimodal Models can achieve higher accuracy in tasks such as image captioning, speech recognition, and sentiment analysis.
- Enhanced Context Understanding: These models can better understand the context by analyzing different types of data together. For example, combining visual and textual information allows the model to grasp the full meaning of a social media post, including any associated emotions or implied messages.
- Greater Versatility: Multimodal Models are versatile and can be applied across a wide range of tasks, from natural language processing to computer vision, making them suitable for diverse applications like healthcare, education, and entertainment.
Challenges in Developing Multimodal Models
Despite their advantages, there are challenges associated with developing and deploying Multimodal Models:
- Data Integration: One of the main challenges is integrating different types of data in a way that the model can effectively learn from. Ensuring that the data is compatible and properly synchronized is crucial for the model’s performance.
- Computational Complexity: Multimodal Models are often more computationally intensive than single-modality models due to the need to process and combine multiple data types. This can lead to higher costs in terms of time and resources.
- Limited Data Availability: High-quality, annotated multimodal datasets are essential for training these models. However, such datasets are often scarce, making it difficult to train models that perform well across all modalities.
Applications of Multimodal Models
The versatility of Multimodal Models allows them to be applied across various industries:
- Healthcare: In healthcare, Multimodal Models can combine medical images, patient records, and clinical notes to assist in diagnosing diseases more accurately.
- Retail and Marketing: In retail, these models can analyze customer reviews, images, and sales data to predict trends and personalize marketing strategies.
- Entertainment and Media: Multimodal Models enhance user experiences in entertainment by enabling more interactive and responsive AI systems, such as virtual assistants that understand both voice commands and facial expressions.
- Education: In education, these models can provide personalized learning experiences by analyzing students’ responses, facial expressions, and engagement levels during lessons.
The Future of Multimodal Models
As AI continues to evolve, Multimodal Models are expected to play a crucial role in advancing the field. Future developments may include:
- Improved Data Fusion Techniques: Research is ongoing to develop better methods for fusing different data types, which could lead to even more accurate and efficient models.
- Enhanced Real-World Applications: As these models become more sophisticated, their applications will expand into new areas, such as autonomous vehicles that can interpret complex driving environments using data from cameras, sensors, and GPS.
- Greater Accessibility and Scalability: Efforts are being made to make Multimodal Models more accessible and scalable, allowing businesses of all sizes to leverage this technology.
Conclusion
Multimodal Models represent a significant advancement in artificial intelligence, offering the ability to process and understand complex data from multiple sources. While challenges remain, the benefits of improved accuracy, context understanding, and versatility make them a promising area of AI research. As technology progresses, Multimodal Models will continue to shape the future of AI, unlocking new possibilities across industries and enhancing the way machines interact with the world.

Leave a comment