Diffusion models have emerged as a powerful tool in machine learning, particularly in generating realistic images, videos, and other complex data structures. These models work by gradually adding noise to data and then learning to reverse this process to generate new samples. If you’re keen to understand how to train a diffusion model, this guide will walk you through the key steps in a straightforward and easy-to-follow manner.
Understanding Diffusion Models
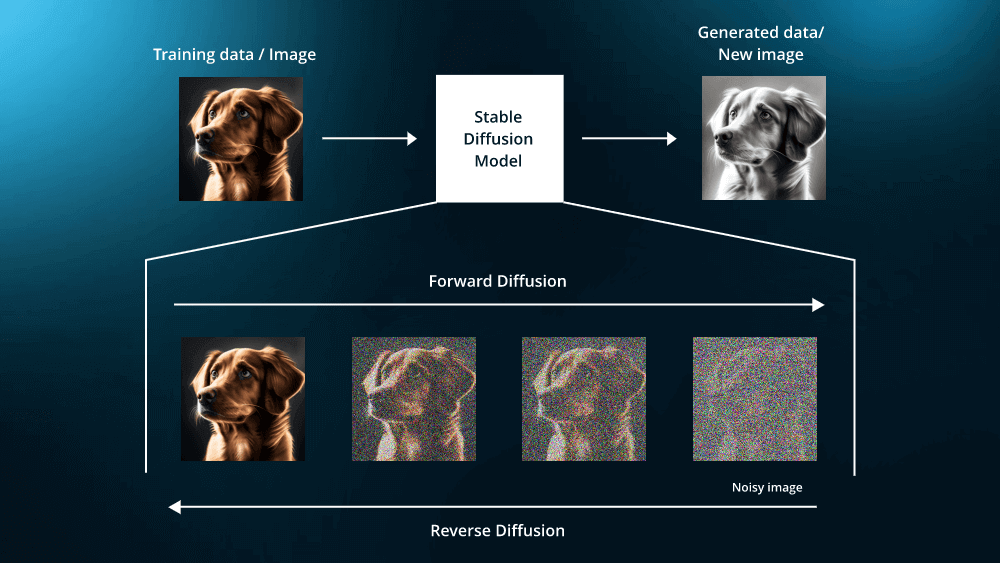
Before delving into how to train a diffusion model, it’s important to grasp the fundamental concept of what a diffusion model is and how it operates. A diffusion model simulates a noise diffusion process, where it begins with clean data and progressively adds random noise to it. The model’s task is to learn how to reverse this noise, eventually generating new data that closely resembles the original. This iterative process is key to how diffusion models can create highly realistic synthetic data.
Step 1: Setting Up Your Environment
The first step in learning how to train a diffusion model is to set up your working environment properly. This includes ensuring you have access to a suitable deep learning framework, such as TensorFlow or PyTorch, and the necessary computing power, ideally with GPU support for faster training.
- Select the Right Tools: Choose a deep learning framework that supports diffusion models. TensorFlow and PyTorch are popular choices due to their flexibility and extensive community support.
- Choose a Suitable Dataset: The choice of dataset depends on your specific application. Popular datasets like CIFAR-10, MNIST, or CelebA are commonly used for image generation tasks. Ensure the dataset is large enough to train the model effectively.
- Set Up Your Computational Resources: Training diffusion models can be computationally intensive, so ensure you have access to adequate hardware, particularly GPUs, which can significantly speed up the training process.
Step 2: Data Preprocessing
Data preprocessing is a critical step in the process of how to train a diffusion model. This step involves preparing your data to ensure it’s in the right format and quality for the model to learn effectively.
- Normalization: The data needs to be normalized, typically by scaling it to a specific range, often between 0 and 1. This ensures that the model can learn more efficiently by reducing the variability in the data.
- Resizing: Depending on the dataset, you may need to resize your data to a uniform shape. For instance, all images should be of the same dimensions to ensure consistent input to the model.
- Data Augmentation: Applying data augmentation techniques, such as random cropping, flipping, or rotation, can help improve the robustness of your model by exposing it to a broader range of variations during training.
Step 3: Designing the Diffusion Model
When learning how to train a diffusion model, the model’s design is crucial. The diffusion model consists of two main components: the forward process, which adds noise to the data, and the reverse process, which denoises it.
- Forward Process: The forward process involves adding noise to the data over several steps. The amount and type of noise added is typically governed by a predefined schedule.
- Reverse Process: The reverse process is where the model learns to remove the noise added during the forward process. This is the core of the training phase, where the model is trained to predict and eliminate noise effectively.
- Model Architecture: The architecture of the diffusion model can vary, but it generally involves using deep neural networks, often convolutional neural networks (CNNs) for image data. The choice of architecture can significantly impact the model’s performance.
Step 4: Training the Diffusion Model
The training phase is the most critical part of understanding how to train a diffusion model. This phase involves feeding your model with the preprocessed data and letting it learn through multiple iterations.
- Loss Function: Define an appropriate loss function that measures the model’s performance in denoising the data. The model will minimize this loss function during training to improve its accuracy.
- Training Process: Train the model by running it through several epochs, where each epoch consists of multiple iterations over your entire dataset. The model adjusts its parameters in each iteration to better reverse the noise added in the forward process.
- Evaluation and Fine-tuning: After initial training, evaluate the model’s performance on a validation set. Fine-tuning might be necessary, adjusting hyperparameters like the learning rate or the noise schedule to improve results.
Step 5: Generating New Data
Once the model is trained, the final step in how to train a diffusion model is using it to generate new data. The trained model starts with random noise and progressively denoises it to produce new data samples.
- Sampling Process: The sampling process involves starting with pure noise and using the trained reverse process to gradually generate a new data instance that resembles the original training data.
- Quality Check: Assess the quality of the generated data. If the results are not satisfactory, you might need to revisit the training process, adjust the model, or fine-tune further.
Conclusion
Understanding how to train a diffusion model involves a series of structured steps, from setting up your environment and preprocessing your data to designing and training the model. By following these steps, you can effectively train a diffusion model capable of generating high-quality synthetic data. As diffusion models continue to evolve, mastering these techniques will be essential for anyone interested in cutting-edge machine learning applications.

Leave a comment