Introduction to Parameter-efficient Fine-tuning (PEFT)
Machine learning has revolutionized many aspects of technology, from natural language processing to computer vision. One of the critical challenges in this field is fine-tuning large pre-trained models for specific tasks. Traditional fine-tuning can be resource-intensive, requiring substantial computational power and memory. Parameter-efficient Fine-tuning (PEFT) emerges as an innovative solution, offering a more efficient and practical approach to fine-tuning models. This article explores the concept of PEFT, its advantages, and its applications in modern machine learning.
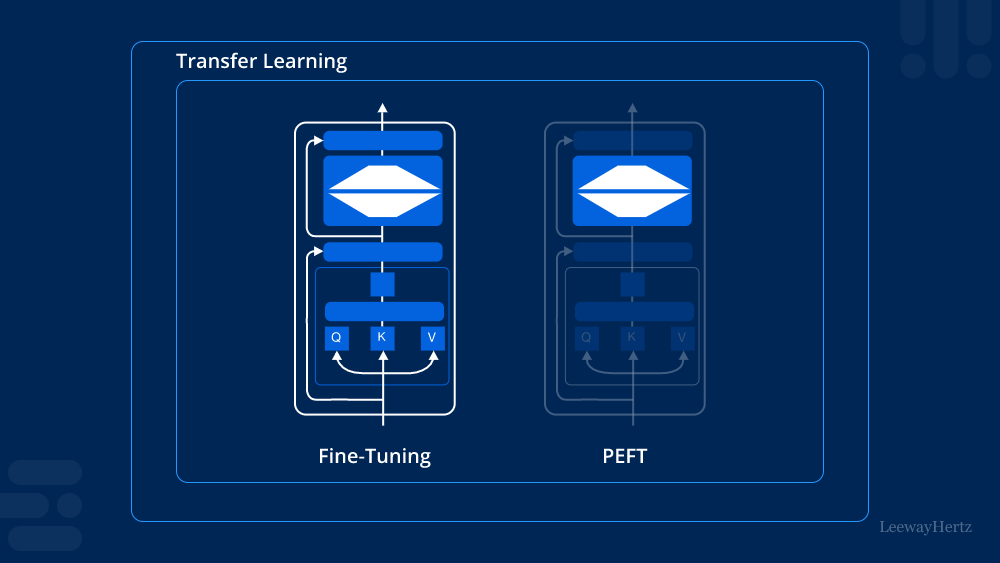
What is Parameter-efficient Fine-tuning (PEFT)?
Parameter-efficient Fine-tuning (PEFT) is a method designed to optimize the fine-tuning process of pre-trained models by updating only a small subset of the model’s parameters. Instead of fine-tuning all the parameters in a large model, PEFT focuses on adjusting a minimal number of parameters while maintaining or even enhancing the model’s performance. This approach significantly reduces the computational resources and time required for fine-tuning, making it accessible and efficient.
The Advantages of Parameter-efficient Fine-tuning (PEFT)
Reduced Computational Costs
One of the primary benefits of Parameter-efficient Fine-tuning (PEFT) is the reduction in computational costs. Traditional fine-tuning can be prohibitively expensive, especially for large models with billions of parameters. PEFT minimizes the number of parameters that need adjustment, leading to faster and more cost-effective fine-tuning processes.
Lower Memory Requirements
PEFT also addresses the issue of high memory usage in traditional fine-tuning. By focusing on a smaller subset of parameters, PEFT requires significantly less memory, making it feasible to fine-tune large models on devices with limited resources, such as edge devices or personal computers.
Improved Performance with Less Data
Parameter-efficient Fine-tuning (PEFT) often leads to improved performance, even when using less data. Traditional fine-tuning methods typically require large datasets to achieve optimal results. PEFT’s selective parameter adjustment can achieve comparable or superior performance with smaller datasets, making it an attractive option for applications where data is scarce or expensive to obtain.
How Parameter-efficient Fine-tuning (PEFT) Works
Selective Parameter Adjustment
The core idea behind PEFT is selective parameter adjustment. Instead of updating all the parameters in a model, PEFT identifies and adjusts only the most critical ones. This selective adjustment ensures that the model learns the new task effectively without the overhead of modifying the entire parameter set.
Techniques for Parameter-efficient Fine-tuning (PEFT)
Several techniques have been developed to implement PEFT. Some popular methods include:
- Adapter Layers: Inserting small adapter layers within the pre-trained model that are fine-tuned for the specific task.
- Parameter Pruning: Identifying and freezing the less important parameters, focusing only on the crucial ones.
- Low-rank Factorization: Decomposing the parameter matrix into low-rank components, allowing selective updates.
Practical Implementation of PEFT
Implementing PEFT requires careful planning and understanding of the model architecture. Here are the general steps involved in applying PEFT:
- Identify Critical Parameters: Use techniques like sensitivity analysis to determine which parameters have the most significant impact on the model’s performance.
- Apply PEFT Technique: Choose a suitable PEFT technique such as adapter layers or parameter pruning.
- Fine-tune the Model: Adjust the identified parameters using the chosen PEFT technique while keeping the rest of the model parameters fixed.
- Evaluate Performance: Assess the model’s performance on the specific task and iterate if necessary.
Applications of Parameter-efficient Fine-tuning (PEFT)
Natural Language Processing (NLP)
In NLP, large pre-trained models like BERT and GPT-3 are commonly used. Parameter-efficient Fine-tuning (PEFT) can significantly reduce the resources required to fine-tune these models for specific tasks such as sentiment analysis, translation, or question answering, making NLP applications more accessible and cost-effective.
Computer Vision
In computer vision, PEFT can be applied to models like convolutional neural networks (CNNs) to optimize them for tasks such as image classification, object detection, or segmentation. By reducing the fine-tuning overhead, PEFT enables the deployment of high-performing vision models on devices with limited computational power.
Edge Computing
Edge computing benefits immensely from Parameter-efficient Fine-tuning (PEFT). Fine-tuning models on edge devices often face constraints like limited computational power and memory. PEFT makes it possible to fine-tune and deploy sophisticated models directly on edge devices, enhancing real-time data processing and decision-making.
Conclusion
Parameter-efficient Fine-tuning (PEFT) is a transformative approach in the field of machine learning, offering a solution to the challenges of traditional fine-tuning methods. By focusing on selective parameter adjustment, PEFT reduces computational costs, lowers memory requirements, and improves performance even with less data. Its applications span across various domains, making advanced machine learning models more accessible and efficient. As the field continues to evolve, Parameter-efficient Fine-tuning (PEFT) stands out as a promising technique for the future of AI and machine learning.

Leave a comment