Introduction to Multimodal Models
In the realm of artificial intelligence (AI), Multimodal Models represent a significant breakthrough. These models are designed to process and integrate information from multiple sources, such as text, images, audio, and video, into a unified understanding. By combining various types of data, Multimodal Models offer a more holistic view of information, enhancing their ability to perform complex tasks with greater accuracy.
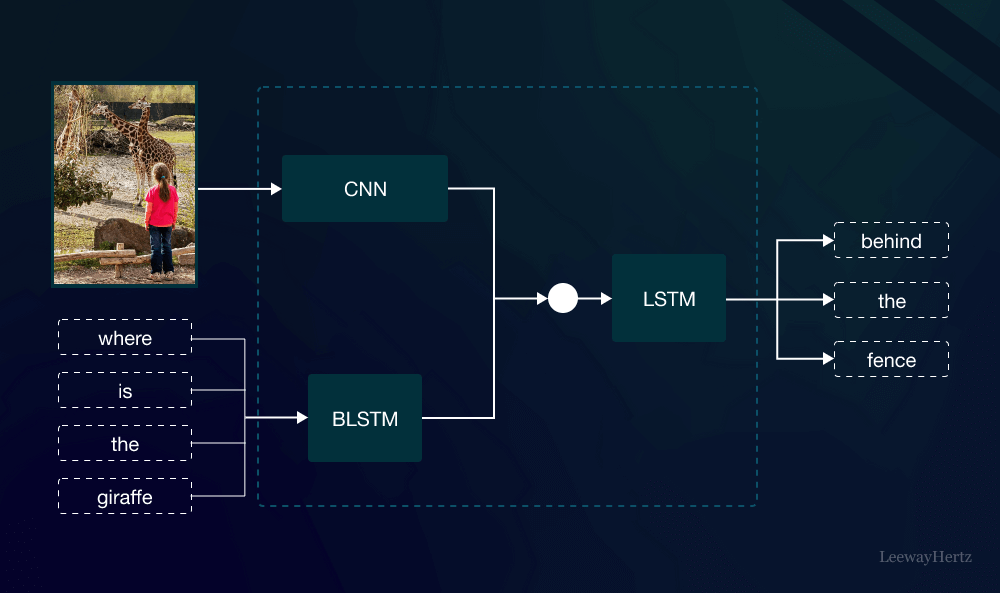
What Are Multimodal Models?
Multimodal Models are sophisticated AI systems that can interpret and analyze data from different modalities simultaneously. Unlike traditional AI models, which are limited to a single type of data—such as text or images—Multimodal Models can handle diverse inputs. For instance, a Multimodal Model might process a combination of text and images to generate more accurate and contextually relevant responses or predictions.
How Do Multimodal Models Work?
The core functionality of Multimodal Models lies in their ability to fuse information from various modalities. This fusion process involves several key steps:
- Data Representation: Each type of input data is first converted into a format that the model can understand. For example, images might be converted into numerical vectors, while text is transformed into embeddings that capture semantic meaning.
- Feature Extraction: The model then extracts relevant features from these representations. For instance, in image processing, features could include shapes, colors, and textures, while in text processing, they might involve keywords and syntactic structures.
- Fusion and Integration: The extracted features from different modalities are combined to create a comprehensive representation. This step is crucial for ensuring that the model can leverage the strengths of each modality to improve overall performance.
- Inference and Output: Finally, the integrated information is used to make predictions, generate responses, or perform other tasks based on the model’s objectives.
Applications of Multimodal Models
Multimodal Models have a wide range of applications across various fields:
- Healthcare: In medical diagnostics, Multimodal Models can analyze medical images (like X-rays and MRIs) alongside patient records and symptoms to provide more accurate diagnoses and treatment recommendations.
- Autonomous Vehicles: Self-driving cars utilize Multimodal Models to interpret data from cameras, radar, and lidar sensors. This integration allows the vehicle to navigate complex environments safely and efficiently.
- Entertainment and Media: In content creation, Multimodal Models can enhance user experience by generating personalized recommendations based on user interactions with text, images, and videos.
- Customer Service: Chatbots and virtual assistants use Multimodal Models to understand and respond to user queries more effectively by processing both text and voice inputs.
Benefits of Multimodal Models
- Improved Accuracy: By integrating information from multiple sources, Multimodal Models can achieve higher accuracy in tasks such as image recognition and natural language understanding.
- Enhanced Contextual Understanding: These models provide a richer understanding of context by considering various types of data, leading to more nuanced and relevant outputs.
- Versatility: Multimodal Models are adaptable and can be applied to diverse domains, making them valuable tools across different industries.
Challenges in Developing Multimodal Models
Despite their advantages, developing Multimodal Models comes with its challenges:
- Data Integration: Combining data from different modalities can be complex due to differences in data formats and structures. Ensuring effective integration requires sophisticated techniques and algorithms.
- Computational Resources: Multimodal Models often require significant computational power and memory due to the complexity of processing and integrating multiple data types.
- Training and Fine-Tuning: Training these models involves handling large datasets and fine-tuning to achieve optimal performance. This process can be resource-intensive and time-consuming.
The Future of Multimodal Models
The field of Multimodal Models is rapidly evolving, with ongoing research focused on addressing current challenges and expanding their capabilities. Future advancements may include:
- Enhanced Efficiency: Improvements in algorithms and hardware may reduce the computational resources required for Multimodal Models, making them more accessible and cost-effective.
- Greater Integration: Continued development in data fusion techniques will enable more seamless integration of diverse data types, leading to even more accurate and reliable models.
- Broader Applications: As Multimodal Models become more advanced, their applications will continue to expand, offering new solutions and innovations across various sectors.
Conclusion
Multimodal Models are paving the way for the next generation of artificial intelligence by enabling more sophisticated and integrated analysis of diverse data types. With their ability to combine and interpret information from multiple sources, these models are set to revolutionize industries ranging from healthcare to entertainment. As research and technology continue to advance, Multimodal Models will undoubtedly play a pivotal role in shaping the future of AI.

Leave a comment