Introduction
In the rapidly evolving field of natural language processing (NLP), optimizing model performance while maintaining efficiency is a constant challenge. Parameter-efficient fine-tuning (PEFT) has emerged as a promising technique to achieve this balance, offering significant improvements in both computational resource utilization and model effectiveness.
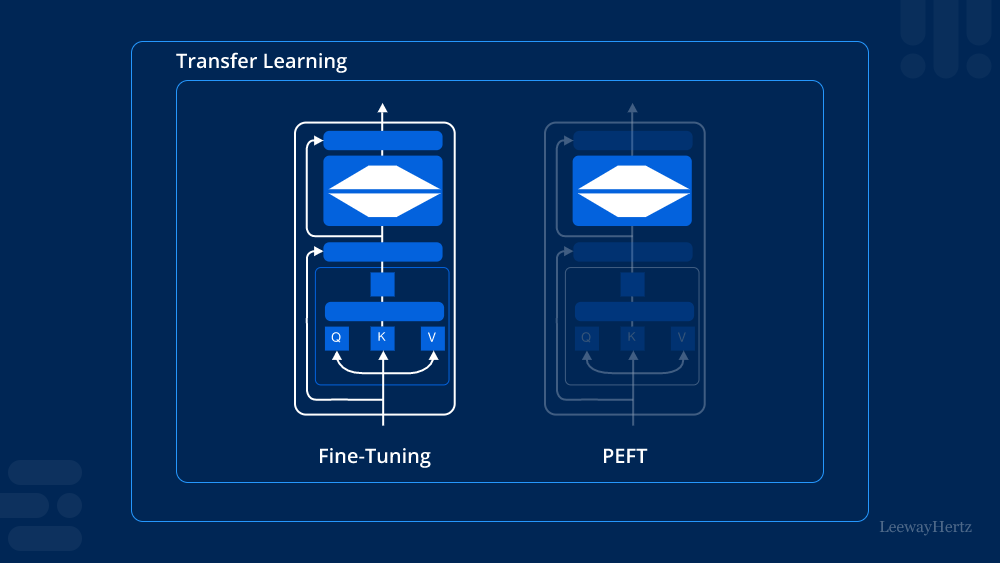
Understanding PEFT
Parameter-efficient fine-tuning (PEFT) refers to a methodology that focuses on enhancing the performance of pre-trained language models with minimal additional parameters. Unlike traditional fine-tuning approaches that may involve adding numerous new parameters, PEFT aims to achieve comparable or even superior results with fewer adjustments. This approach is particularly advantageous in scenarios where computational resources are limited or where model deployment speed is critical.
Key Benefits of PEFT
- Resource Efficiency: By minimizing the number of additional parameters introduced during fine-tuning, PEFT reduces the computational burden associated with training and inference. This efficiency is crucial for scaling models to handle large datasets or deploying them in resource-constrained environments.
- Retaining Generalization: Despite its parameter-efficient nature, PEFT maintains the generalization capabilities of pre-trained models. This means that the models retain their ability to perform well across a wide range of tasks and domains, making them versatile solutions for various NLP applications.
- Faster Adaptation: PEFT allows models to adapt quickly to new datasets or tasks. The reduced number of parameters speeds up the fine-tuning process without sacrificing performance, enabling rapid deployment and iteration in real-world applications.
Implementation of PEFT
Implementing PEFT involves several key steps:
- Selection of Pre-trained Model: Choose a suitable pre-trained language model based on the specific task requirements and available computational resources.
- Fine-tuning Strategy: Develop a fine-tuning strategy that focuses on modifying existing parameters judiciously rather than adding new ones. This might involve adjusting learning rates, batch sizes, or specific layers of the model.
- Evaluation and Iteration: Evaluate the fine-tuned model on validation data to ensure it meets performance metrics. Iterate on the fine-tuning process as necessary to optimize results.
Future Directions
As the field of NLP continues to advance, the application of PEFT holds promise for several future directions:
- Integration with Transfer Learning: Explore how PEFT can complement transfer learning techniques to further enhance model adaptation and generalization across diverse tasks and domains.
- Optimization Algorithms: Develop new optimization algorithms tailored for PEFT to improve efficiency and scalability in large-scale model deployments.
- Domain-Specific Applications: Investigate the application of PEFT in specialized domains such as medical text analysis, legal document processing, and customer support automation.
Conclusion
Parameter-efficient fine-tuning (PEFT) represents a significant advancement in optimizing the performance and efficiency of pre-trained language models. By focusing on minimal parameter adjustments, PEFT enables faster adaptation, reduces computational overhead, and maintains high levels of model generalization. As NLP applications continue to grow in complexity and scale, PEFT is poised to play a crucial role in enhancing model deployment and effectiveness across various domains.

Leave a comment