Introduction:
In today’s data-driven world, large language models (LLMs) have emerged as powerful tools for various applications, from natural language processing to content generation and beyond. However, for enterprises seeking to harness the full potential of LLMs for proprietary purposes, building them requires a strategic approach and meticulous execution. This article delves into the intricacies of constructing enterprise-grade proprietary LLMs, offering insights, strategies, and best practices for success.
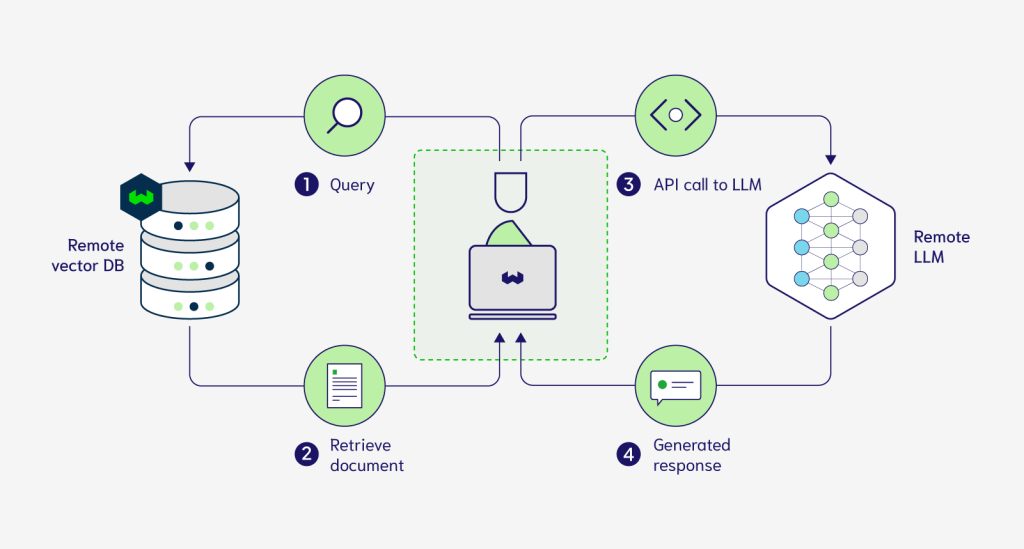
Understanding the Foundations:
Before embarking on the journey of building enterprise-grade proprietary LLMs, it’s crucial to lay a solid foundation. This entails a deep understanding of the underlying technologies, including neural networks, natural language processing (NLP), and machine learning algorithms.
- Define Objectives and Use Cases:
Begin by clearly defining the objectives and intended use cases for the proprietary LLM. Whether it’s enhancing customer service through chatbots, automating content creation, or analyzing vast amounts of text data, having a precise understanding of the desired outcomes is paramount. - Data Acquisition and Preprocessing:
Next, focus on data acquisition and preprocessing. Enterprises must gather high-quality, domain-specific data relevant to their objectives. This may involve proprietary datasets, publicly available corpora, or data obtained through partnerships. Preprocessing steps such as cleaning, tokenization, and normalization are essential to ensure data quality and consistency.
Building the Architecture:
With the foundational elements in place, attention shifts to designing and implementing the architecture for the proprietary LLM.
- Selecting the Right Framework and Infrastructure:
Choose an appropriate deep learning framework (e.g., TensorFlow, PyTorch) and infrastructure that aligns with the organization’s resources and requirements. Consider factors such as scalability, performance, and compatibility with existing systems. - Model Design and Training:
Develop a custom architecture tailored to the specific objectives and data characteristics. Experiment with different architectures, such as transformer-based models (e.g., GPT, BERT), recurrent neural networks (RNNs), or hybrid approaches. Train the model using large-scale computational resources, leveraging techniques like distributed training and transfer learning to expedite the process. - Fine-Tuning and Optimization:
Fine-tune the model to enhance performance on domain-specific tasks and optimize its efficiency. This may involve adjusting hyperparameters, incorporating regularization techniques, or implementing specialized optimization algorithms. Continuous monitoring and iteration are essential to refine the model’s capabilities over time.
Ensuring Security and Compliance:
As enterprises handle sensitive data and proprietary information, ensuring the security and compliance of proprietary LLMs is paramount.
- Data Privacy and Protection:
Implement robust measures to safeguard data privacy and protection throughout the model development lifecycle. Employ encryption, access controls, and anonymization techniques to mitigate risks associated with data breaches and unauthorized access. - Compliance with Regulations:
Adhere to relevant regulations and industry standards governing data privacy, such as GDPR, HIPAA, or CCPA. Conduct thorough audits and assessments to ensure compliance with legal and ethical requirements, fostering trust and transparency with stakeholders.
Deployment and Integration:
Once the proprietary LLM is developed and validated, the focus shifts to deployment and integration into existing workflows and applications.
- Scalable Deployment Strategies:
Deploy the proprietary LLM using scalable and efficient deployment strategies, such as containerization (e.g., Docker), serverless computing, or cloud-based services. Ensure seamless integration with existing infrastructure and applications to maximize usability and accessibility. - Continuous Monitoring and Maintenance:
Establish robust monitoring mechanisms to track the performance, reliability, and security of the deployed LLM in real-time. Implement automated alerts and proactive maintenance procedures to address issues promptly and ensure optimal functionality. - Integration with Business Processes:
Integrate the proprietary LLM into relevant business processes and applications to drive tangible value and achieve organizational objectives. Collaborate closely with cross-functional teams to identify opportunities for leveraging LLM capabilities across various departments and use cases.
Conclusion:
Building enterprise-grade proprietary large language models requires a comprehensive approach that encompasses data acquisition, model development, security, compliance, deployment, and integration. By following the strategies and best practices outlined in this article, enterprises can harness the full potential of LLMs to unlock new opportunities, enhance decision-making, and drive innovation in a data-driven world.

Leave a comment